
INTRODUCTION
UNORDERED MAP in Cpp
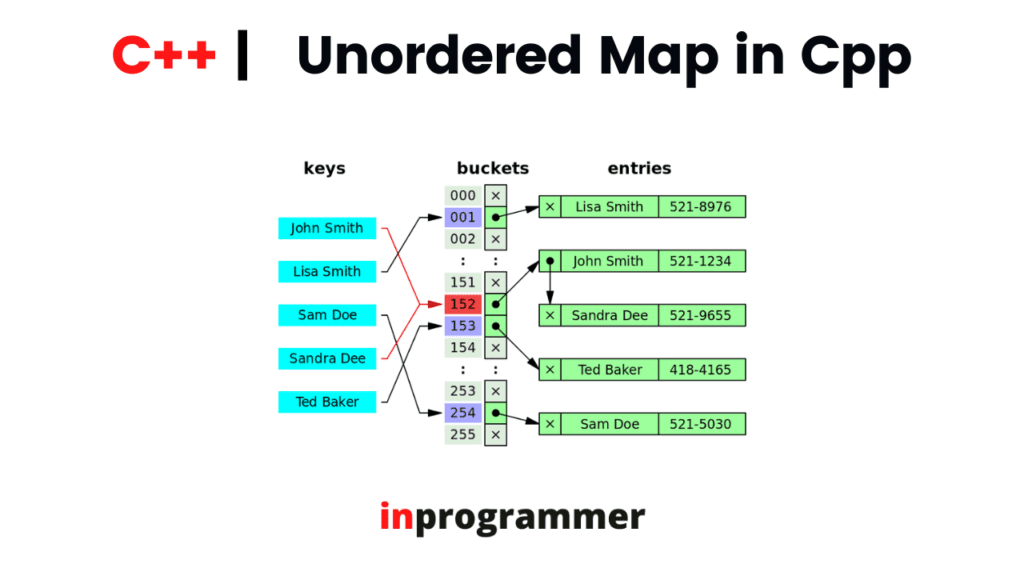
In this tutorial, we are going to learn about unordered_map in the standard template library from C++. an unordered_map is an associative container the same as a normal map which stores items consisting of key-value and mapped value pairs. The key values in the unordered_maps are unique, that is no two mapped values cannot have the same key value. The key values in the maps are used for sorting and identifying the elements and the mapped values are used to store the content of the respective key.
Here are some of the points noted about the unordered_map.
- Unordered_maps store the mapped values associated with unique key values stored in the order based on the order in which they are inserted.
- The keys in unordered_maps are used for faster searching of the values associated with them.
- Only one value is associated with one key value.
- Unordered_maps used hash tables for implementation. Unordered_maps can be used as an associative array.
let’s look at the syntax of the map container.
unordered_map< key_datatype , value_datatype > unorderedmap_name;Where key_datatype and value_datatype represent the datatypes of the key and values respectively.
The example syntax for the unordered_map is.
unordered_map<char, int>mp = { {'H', 21} ,
{'I', 52} ,
{'J', 36} ,
{'K', 47},
{'L', 54} };* The key-value in the unordered_maps are hashed into indices of a hash table that’s why the performance of the unordered_map container depends on the hash function mostly. The average time taken to perform the search, delete and insert element on the unordered_map is O( 1 ).
* Worst case of time complexity for the above operations can go up from O( 1 ) to O( n * n ).
Let’s look at some of the basic methods that are performed on the unordered_maps.
at(): this method returns the reference of the mapped value associated with the key value.
insert(): this method adds a new item to the unordered_map in a specific order
erase(): this method removes the particular item from the unordered_map.
begin(): this method returns an iterator to the first element in the unordered_map.
end(): this method returns an iterator to the last element in the unordered_map.
count(): this method is used to return the number of items stored in the unordered_map.
empty(): this method returns a boolean value whether the particular unordered_map is empty or not.
clear(): this method is used to remove all the elements from the unordered_map and empty it.
These are some of the basic methods that are implemented on the unordered_map container.
Let’s look at a sample program implementing the unordered_map container.
#include <iostream>
#include <unordered_map>
#include <string>
using namespace std;
int main() {
unordered_map<int, string> umap;
umap.insert(make_pair(1,"alice"));
umap.insert(make_pair(2,"john"));
umap.insert(make_pair(3,"carry"));
umap.insert(make_pair(4,"leo"));
umap.insert(make_pair(5,"james"));
unordered_map<int, string>:: iterator itr;
cout << "All Elements : \n\n";
for (itr = umap.begin(); itr != umap.end(); itr++)
{
cout << (*itr).first << ": " << (*itr).second << endl;
}
}
The output of the program is.
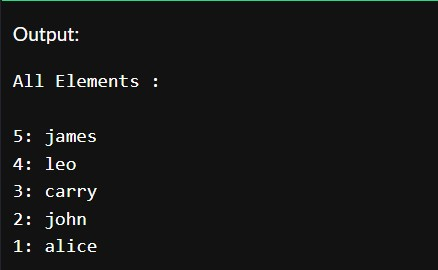
In the above program, we have included the <unordered_map> to create the unordered_map container. After creating, we have inserted key-value and mapped value pairs using the insert(make_pair()) method. Then we created an iterator to traverse over the unordered_map.
The map and the unordered_map are almost similar, then what is the one thing that differentiates the map from the unordered_map?
Let’s look at the differences between the map and the unordered_map.
| MAP | UNORDERED_MAP |
| The maps are implemented using the binary search tree | The unordered_maps are implemented using the hash tables. |
| The items in the map are stored in the increasing order of the key_value regardless of how they are inserted. | The items in the unordered_map are stored in the order in which they are inserted. |
| For searching an item: O( logN ) | For searching an item: O( 1 ) ->average time complexity O( n ) -> worst time complexity |
| For insertion and deletion : O( logN ) | For insertion and deletion : O( 1 ) -> average time complexity O( n ) -> worst time complexity |
CONCLUSION
That’s it from this tutorial. We have learned about the unordered_map container, its properties, basic methods that are implemented on unordered_maps and differences between the maps and the unordered_maps. Hope you guys found it interesting. Happy Coding!
