

In this article, we will learn how to download Online articles as PDFs using python script.
Introduction:
Let’s create a PDF Downloader for online articles and make our lives a little bit easier using python.
Downloading articles as PDFs is very important and becomes handy in our day-to-day lives. Did anyone think about creating our own program to download articles as PDFs by ourselves?
and what if I tell you!! You can do the same things with the help of a simple python script.
Outline:
In this project, we will take the article link of any online article site like inprogrammer.com or GeeksForGeeks and give it as input for our python script and run it. After running the script we are redirected to the article link and the whole website will be saved as a PDF to our local PC.
Project Prerequisites:
You have to install only three packages in your system to run this script. Because we have to use the web driver in our project. We use Google Chrome as our browser for this project, make sure you have google chrome installed on your PC. We use the requests module to redirect to the respective website using the link provided as the input. We import the JSON module for our project.
selenium: Python language bindings for Selenium WebDriver.
The selenium package is used to automate web browser interaction from Python.
Home: https://selenium.dev
Docs: selenium package API
Dev: https://github.com/SeleniumHQ/Selenium
PyPI: https://pypi.org/project/selenium/
IRC: #selenium channel on LiberaChat
Several browsers/drivers are supported (Firefox, Chrome, Internet Explorer), as well as the Remote protocol.
Supported Python Versions:
- Python 3.7+
to know more about selenium, refer to this link: https://pypi.org/project/selenium/
webdriver_manager: The main idea is to simplify the management of binary drivers for different browsers.
For now, support:
Compatible with Selenium 4.x and below.
to know more about webdriver_manager, refer to this link:
https://pypi.org/project/webdriver-manager/
JSON: to know more about JSON, refer to this link: https://www.w3schools.com/python/python_json.asp
requests: Requests allow you to send HTTP/1.1 requests extremely easily. There’s no need to manually add query strings to your URLs, or to form-encode your PUT & POST data — but nowadays, just use the JSON method!
Requests is one of the most downloaded Python packages today, pulling in around 30M downloads/week— according to GitHub, Requests is currently depended upon by 1,000,000+ repositories. You may certainly put your trust in this code.
commands to install packages
> pip install selenium
> pip install webdriver_manager
>pip install requests
Code Implementation:
The first thing we need to do is to import the required packages and modules. In this project, we import thwebdriver, JSON module to make use of its functions. We will import webdriver from the selenium package and ChromeDriverManager from webdriver_manager.chrome.
from selenium import webdriver
from webdriver_manager.chrome import ChromeDriverManager
import JSON
import requests
from selenium import webdriver
from webdriver_manager.chrome import ChromeDriverManager
import JSON
import requests
Next, we will be defining a function called get_driver.In this function, we define settings as recentDestinations and define all the required parameters. At the end of the function, we return the browser object.
def get_driver():
# chrome options settings
chrome_options = webdriver.ChromeOptions()
settings = {
“recentDestinations”: [
{“id”: “Save as PDF”, “origin”: “local”, “account”: “”}
],
“selectedDestinationId”: “Save as PDF”,
“version”: 2,
}
prefs = {
“printing.print_preview_sticky_settings.appState”: json.dumps(settings)
}
chrome_options.add_experimental_option(“prefs”, prefs)
chrome_options.add_argument(“–kiosk-printing”)
# launch browser with predefined settings
browser = webdriver.Chrome(
executable_path=ChromeDriverManager().install(), options=chrome_options
)
return browser
def get_driver():
# chrome options settings
chrome_options = webdriver.ChromeOptions()
settings = {
"recentDestinations": [
{"id": "Save as PDF", "origin": "local", "account": ""}
],
"selectedDestinationId": "Save as PDF",
"version": 2,
}
prefs = {
"printing.print_preview_sticky_settings.appState": json.dumps(settings)
}
chrome_options.add_experimental_option("prefs", prefs)
chrome_options.add_argument("--kiosk-printing")
# launch browser with predefined settings
browser = webdriver.Chrome(
executable_path=ChromeDriverManager().install(), options=chrome_options
)
return browser
In the next section, we define another function called download_article() and we will get the driver through the URL. We execute the script with a window. print() as its parameter. We close the browser at the end of the function.
def download_article(URL):
browser = get_driver()
browser.get(URL)
# launch print and save as pdf
browser.execute_script(“window.print();”)
browser.close()
def download_article(URL):
browser = get_driver()
browser.get(URL)
# launch print and save as pdf
browser.execute_script("window.print();")
browser.close()
In the last section, we will start defining the main function, where we will take the input from the user. If the URL provided by the user is not valid, we will again prompt you to enter a valid URL.
if __name__ == “__main__”:
URL = input(“provide article URL: “)
# check if the url is valid/reachable
if requests.get(URL).status_code == 200:
try:
download_article(URL)
print(“Your article is successfully downloaded”)
except Exception as e:
print(e)
else:
print(“Enter a valid working URL”)
if __name__ == "__main__":
URL = input("provide article URL: ")
# check if the url is valid/reachable
if requests.get(URL).status_code == 200:
try:
download_article(URL)
print("Your article is successfully downloaded")
except Exception as e:
print(e)
else:
print("Enter a valid working URL")
Yes. We have now completed the code implementation.
Sourcen Code:
Here is the complete source code of the project.
# !/usr/bin/env python
from selenium import webdriver
from webdriver_manager.chrome import ChromeDriverManager
import json
import requests
# article url
# URL = "https://www.geeksforgeeks.org/what-can-i-do-with-python/"
def get_driver():
# chrome options settings
chrome_options = webdriver.ChromeOptions()
settings = {
"recentDestinations": [
{"id": "Save as PDF", "origin": "local", "account": ""}
],
"selectedDestinationId": "Save as PDF",
"version": 2,
}
prefs = {
"printing.print_preview_sticky_settings.appState": json.dumps(settings)
}
chrome_options.add_experimental_option("prefs", prefs)
chrome_options.add_argument("--kiosk-printing")
# launch browser with predefined settings
browser = webdriver.Chrome(
executable_path=ChromeDriverManager().install(), options=chrome_options
)
return browser
def download_article(URL):
browser = get_driver()
browser.get(URL)
# launch print and save as pdf
browser.execute_script("window.print();")
browser.close()
if __name__ == "__main__":
URL = input("provide article URL: ")
# check if the url is valid/reachable
if requests.get(URL).status_code == 200:
try:
download_article(URL)
print("Your article is successfully downloaded")
except Exception as e:
print(e)
else:
print("Enter a valid working URL")
As we have completed the project, let us check the output.
Output:

After running the above-given command, it will prompt you to enter the URL of the article.
In this example I will enter the URLs of inprogrammer.com article and GFG article.
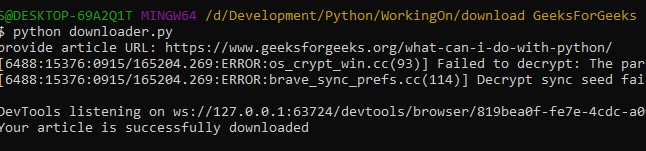
After running the source code, a new window will appear like the following:
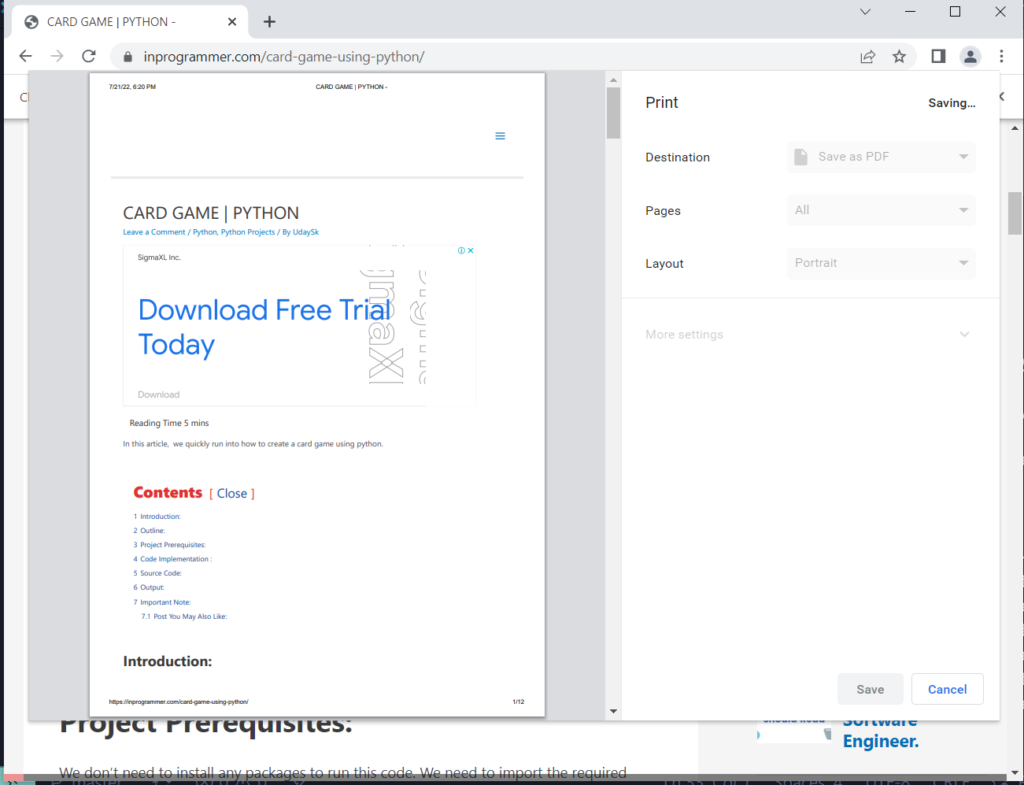
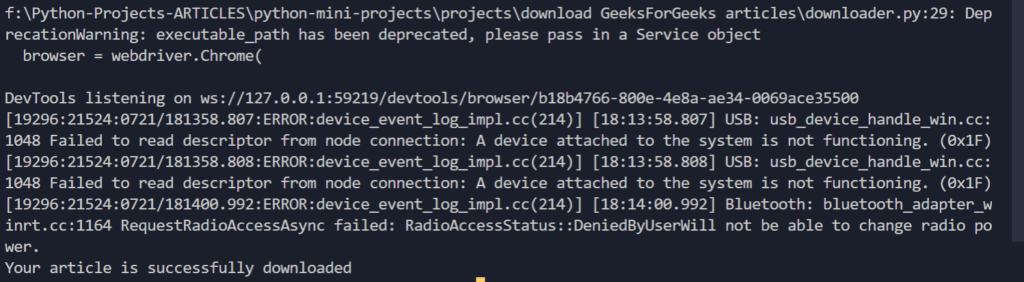
These are the screenshots of the output after running the script.
Alright, Congratulations! We have successfully learned how to create a PDF downloader for online articles using python.
Important Note:
If you still did not get the output correctly/article is not downloaded as PDF, refer to the documentation of the packages. Drop your issues as the comments below.
Go to the documentation of the packages: selenium, webdriver_manager, and requests package to know more about them.
Happy Coding.
Thank You!
By UdaySk
